202501272236 Distributing Cluster Volumes
Continuing upon the expedition of improving my homelab and integrating it with 202501272235 Kubernetes Through K3s, the main conundrum next was to figure out and research the various ways you can handle cluster data stores. There are two components here
- The Kubernetes backend
- Node and pod-level volume
For point (1) - Kubernetes needs a backend to maintain the cluster state. By default, Kubernetes uses etcd to store cluster data.
For point (2) – nodes and pods that require persistent volume need a persistent datastore. Otherwise, the volumes will disappear the moment the pod gets restarted. This is critical in situations where the application needs to store a file persistently.
Kubernetes Backend
With K3s, it offers the ability to go beyond etcd as the datastore, which I listed as one of the goals to make the homelab portable. By using a distributed cluster data store, I can consider alternatives such as an external database or even a distributed version of etcd.
Effectively, point (1) will be tackled by the use of a distributed embedded etcd as a way to handle cluster datastore that is resilient and persistent. Distributed embedded etcd will be handled at the server level - the control planes.
I will put this image architecture for reference.
Longhorn Rescues The Pods
Longhorn, which is a CNCF-backed project, funded by SUSE will become the storage orchestration engine. Longhorn will be performing the PV and PVC claims for the nodes and pods.
Longhorn is a way of orchestrating multiple block-level storage (in my case, NVMe M.2 SSDs, attached to each Pi5) to act as one singular, persistent data store.
Here is an architecture read/write flow.
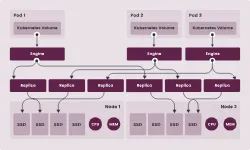
Using a distributed persistent engine like Longhorn offers a few benefits
- Pod and node volumes are distributed across compute nodes. If a pod that had persistent volume in
worker-pi-home-01gets redeployed intoworker-pi-home-02the pod can potentially resume its original state. As the volume claims are “shared”, even if the pod gets redeployed into anotheragent– I’m certain the state will remain consistent. - Longhorn decouples from network-level block storage
- I’ve used NFS before (with Kubeadm, csi-drivers, yada yada) and I did not find it to be an enjoyable experience. It made the cluster tightly coupled to a centralised storage space, that by itself, was quite fragile.
- Longhorn provides backup alternatives, either through NFS or S3-like compatible storage. This is a big boon for me – as much as I complained about NFS in the prior point, I’d like to imagine it can be useful as a backup choice.
Ideally, with Longhorn, I can add new compute nodes into the cluster, regardless of spatial constraints. The new node, with new block storage(s) ideally in the same form factor, would seamlessly blend into the cluster and sync towards eventual state.